 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Value Alignment for Generative Recommendation in Industrial Advertising
May 07, 2026Generative Recommendation (GR) reformulates recommendation as a next-token generation problem and has shown promise in industrial applications. However, extending GR to industrial advertising is non-trivial because the system must optimize not only user interest but also commercial value. Existing GR pipelines remain largely semantics-centric, making it difficult to align value signals across tokenization, decoding, and online serving. To address this issue, we propose UniVA, a Unified Value Alignment framework for advertising recommendation. We first introduce a Commercial SID tokenizer that injects value-related attributes into SID construction, yielding value-discriminative item representations. We then develop a Generation-as-Ranking SID Decoder jointly optimized by supervised learning and eCPM-aware reinforcement learning, which fuses value scores into next-item SID generation to perform generation and ranking in one decoding process. Finally, we design a value-guided personalized beam search that reuses generation-as-ranking logits as online value guidance and applies a personalized trie tree to constrain decoding to request-valid SID paths. Experiments on the Tencent WeChat Channels advertising platform show that UniVA achieves a 37.04\% improvement in offline Hit Rate@100 over the baseline and a 1.5\% GMV lift in online A/B tests.
Tencent Advertising Algorithm Challenge 2025: All-Modality Generative Recommendation
Apr 04, 2026Generative recommender systems are rapidly emerging as a new paradigm for recommendation, where collaborative identifiers and/or multi-modal content are mapped into discrete token spaces and user behavior is modelled with autoregressive sequence models. Despite progress on multi-modal recommendation datasets, there is still a lack of public benchmarks that jointly offer large-scale, realistic and fully all-modality data designed specifically for generative recommendation (GR) in industrial advertising. To foster research in this direction, we organised the Tencent Advertising Algorithm Challenge 2025, a global competition built on top of two all-modality datasets for GR: TencentGR-1M and TencentGR-10M. Both datasets are constructed from real de-identified Tencent Ads logs and contain rich collaborative IDs and multi-modal representations extracted with state-of-the-art embedding models. The preliminary track (TencentGR-1M) provides 1 million user sequences with up to 100 interacted items each, where each interaction is labeled with exposure and click signals, while the final track (TencentGR-10M) scales this to 10 million users and explicitly distinguishes between click and conversion events at both the sequence and target level. This paper presents the task definition, data construction process, feature schema, baseline GR model, evaluation protocol, and key findings from top-ranked and award-winning solutions. Our datasets focus on multi-modal sequence generation in an advertising setting and introduce weighted evaluation for high-value conversion events. We release our datasets at https://huggingface.co/datasets/TAAC2025 and baseline implementations at https://github.com/TencentAdvertisingAlgorithmCompetition/baseline_2025 to enable future research on all-modality generative recommendation at an industrial scale. The official website is https://algo.qq.com/2025.
DiffuReason: Bridging Latent Reasoning and Generative Refinement for Sequential Recommendation
Feb 12, 2026Latent reasoning has emerged as a promising paradigm for sequential recommendation, enabling models to capture complex user intent through multi-step deliberation. Yet existing approaches often rely on deterministic latent chains that accumulate noise and overlook the uncertainty inherent in user intent, and they are typically trained in staged pipelines that hinder joint optimization and exploration. To address these challenges, we propose DiffuReason, a unified "Think-then-Diffuse" framework for sequential recommendation. It integrates multi-step Thinking Tokens for latent reasoning, diffusion-based refinement for denoising intermediate representations, and end-to-end Group Relative Policy Optimization (GRPO) alignment to optimize for ranking performance. In the Think stage, the model generates Thinking Tokens that reason over user history to form an initial intent hypothesis. In the Diffuse stage, rather than treating this hypothesis as the final output, we refine it through a diffusion process that models user intent as a probabilistic distribution, providing iterative denoising against reasoning noise. Finally, GRPO-based reinforcement learning enables the reasoning and refinement modules to co-evolve throughout training, without the constraints of staged optimization. Extensive experiments on four benchmarks demonstrate that DiffuReason consistently improves diverse backbone architectures. Online A/B tests on a large-scale industrial platform further validate its practical effectiveness.
Stock Market Trend Analysis Using Hidden Markov Model and Long Short Term Memory
Apr 20, 2021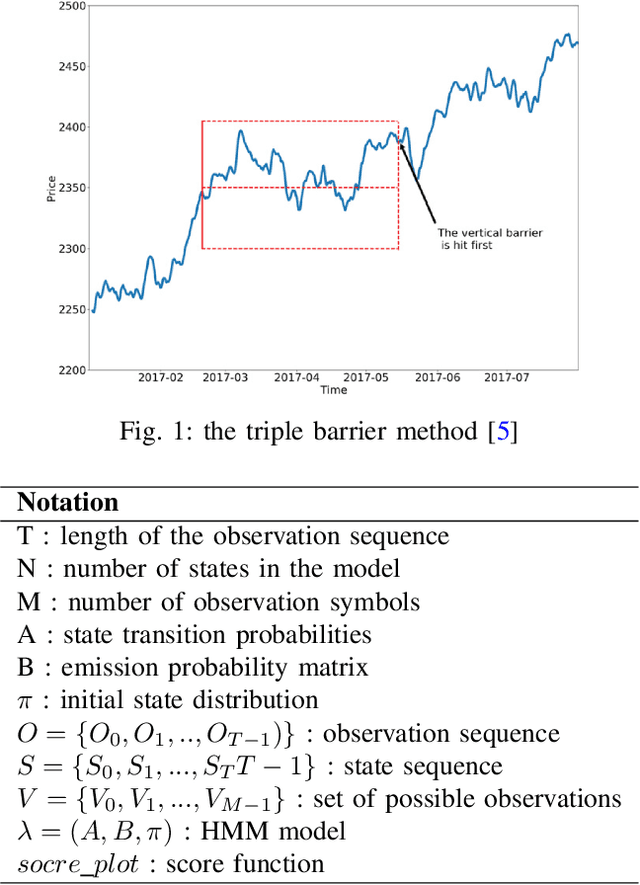
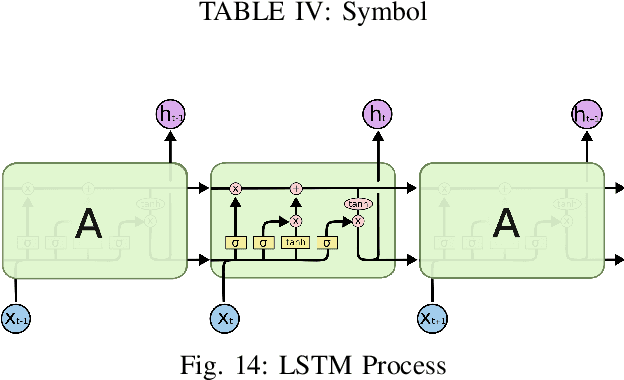
This paper intends to apply the Hidden Markov Model into stock market and and make predictions. Moreover, four different methods of improvement, which are GMM-HMM, XGB-HMM, GMM-HMM+LSTM and XGB-HMM+LSTM, will be discussed later with the results of experiment respectively. After that we will analyze the pros and cons of different models. And finally, one of the best will be used into stock market for timing strategy.